EYREIN PRODUCTS
Eyrein Products — Web Scraper & API
 Requests
BeautifulSoup
FLASK
JSON
PDF
Requests
BeautifulSoup
FLASK
JSON
PDF
Eyrein Products est un projet de scraping web qui automatise la collecte de fiches techniques et de sécurité pour les produits de nettoyage de l'entreprise Eyrein. Le projet combine scraping (BeautifulSoup/Requests), stockage (JSON), téléchargement (PDF), et exposition via API REST (Flask).
🎯 Objectifs du projet
- Scraper la boutique Eyrein : Récupérer tous les produits de nettoyage du site
- Extraire les métadonnées : Nom, référence (REF), URLs fiches techniques, fiches de sécurité, images
- Structurer en JSON : Organiser par catégories avec relations produits
- Télécharger les PDFs : Automatiser DL des fiches + images produit
- Créer une API : Exposer données via Flask (JSON/HTML) pour site entreprise
- Filtrer les produits utilisés : Endpoint privé (avec clé API) pour produits de l'entreprise
📐 Architecture & Structure
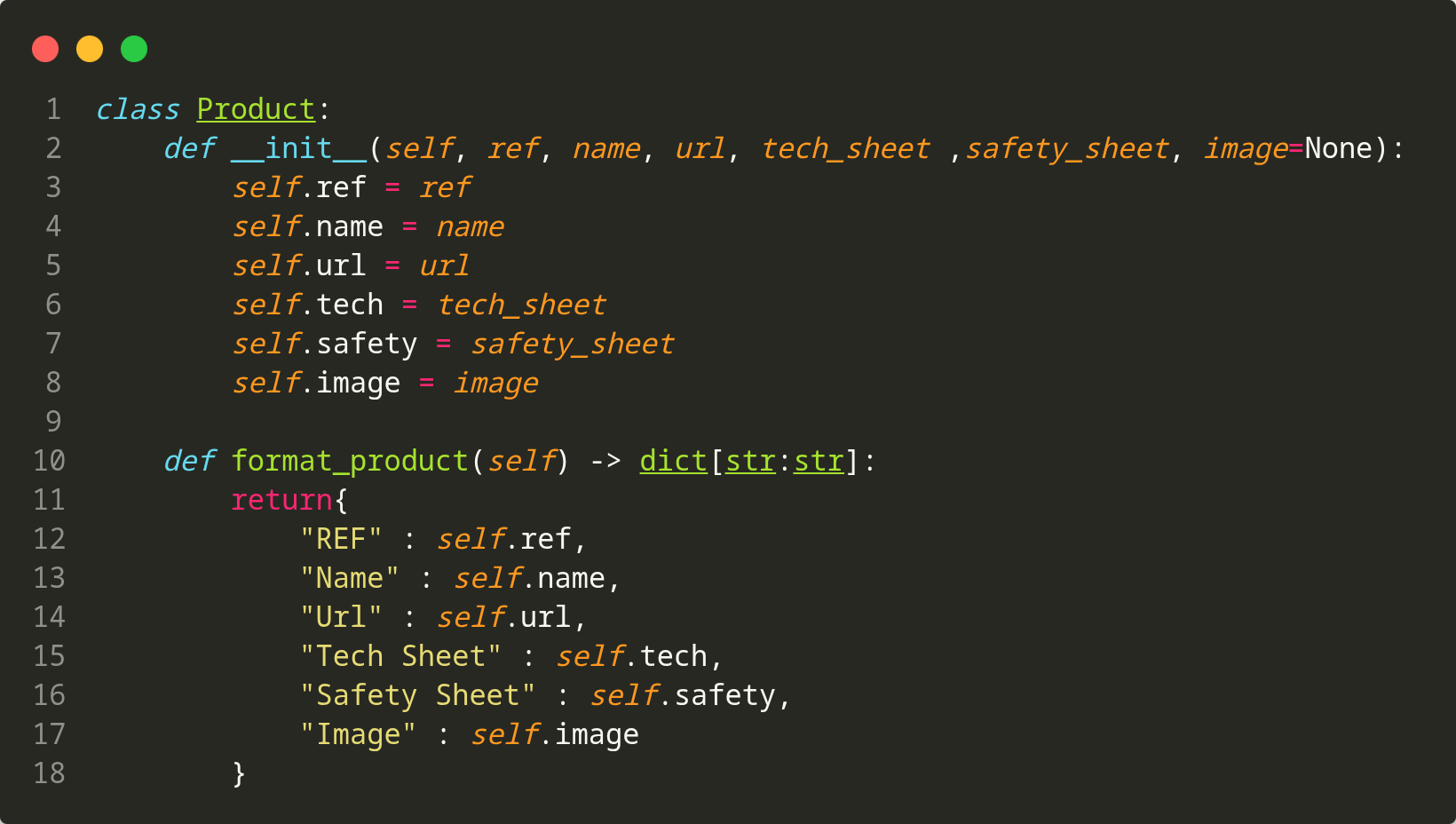
- src/classes/ : OOP pour Product et Category (format_product, format_category)
- src/functions.py : Scraping avec BeautifulSoup (get_page, get_element, get_all_pages, get_data_from_web)
- downloading/download.py : Téléchargement PDFs + images + création ZIPs par produit
- my_api/api.py : Flask app avec 3 endpoints (tous produits, un produit, mes produits)
- src/CONST.py : Configuration (URLs, CSS selectors, chemins fichiers)
- data/data.json : Base de données persistante (catégories + produits)
🕷️ Web Scraping (BeautifulSoup + Requests)
- get_page(session, url) : Fetch HTTP + parsing BeautifulSoup
- get_all_pages(session, url) : Détecte nombre total de pages (pagination) via selector '.pager a'
- CSS Selectors : Cibles précises (ex: '.column.small-12.medium-6.large-4 a', '.product--title')
- Déduplication : Set seen_products pour éviter doublons lors pagination
- Extraction : Nom, REF (référence produit), URLs fiches tech/sécurité, image produit
- Logging : Trace complète (succès / erreurs) en stdout + fichier
- Session persistante : Requests.Session() pour header/cookies gérés

📊 Modèle de données (JSON)
- Category : { "Category Name", "Category URL", "Products": [...] }
- Product : { "REF", "Name", "Url", "Tech Sheet" (PDF link), "Safety Sheet" (PDF link), "Image" }
- Format : Array of categories, persisté en data/data.json
- Hydratation : json_to_object() convertit JSON → instances Product/Category
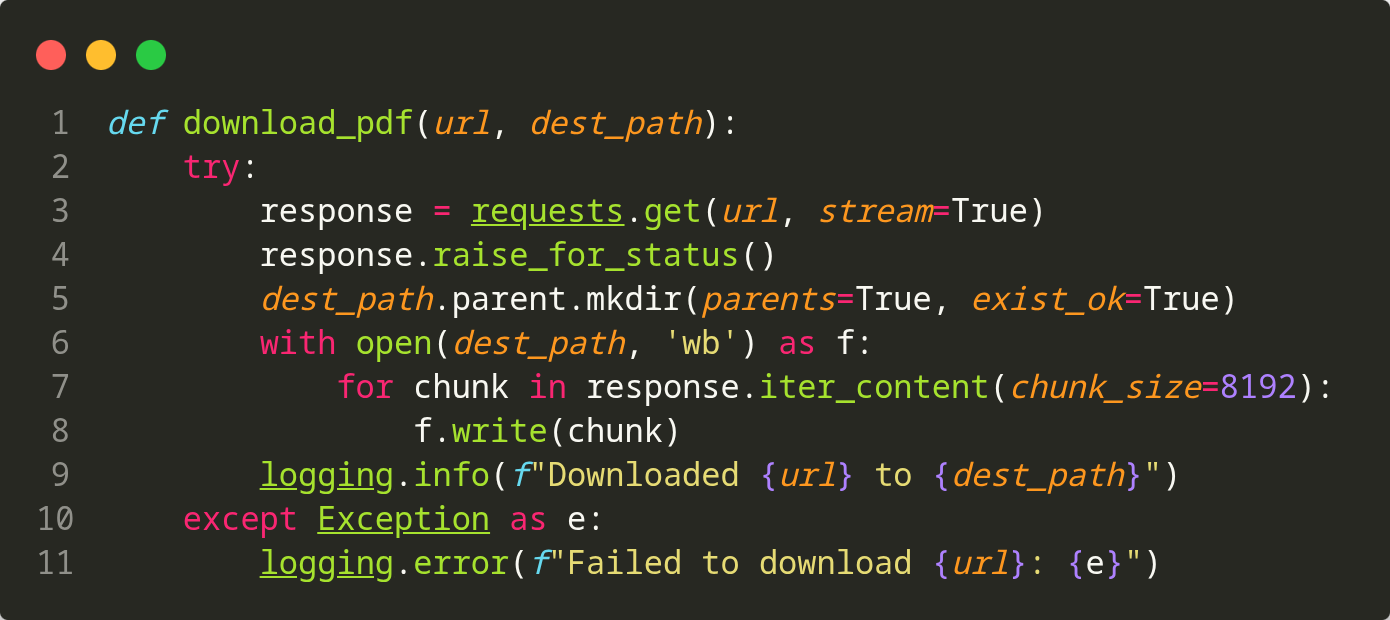
📥 Pipeline de téléchargement (downloading/download.py)
- construct_all_dirs() : Crée répertoire par produit utilisé (Produits-nettoyage/NomProduit/)
- download_pdf(url, dest_path) : Stream-based PDF DL (chunks 8KB), gestion erreurs
- Télécharge : Fiche technique PDF, fiche de sécurité PDF, image produit JPG
- create_dirs() : Création répertoires parents récursifs
- ZIP d'archive : Compresse fiches pour chaque produit (NomProduit_FICHES.zip)
- Logging détaillé : Success/erreurs chaque téléchargement
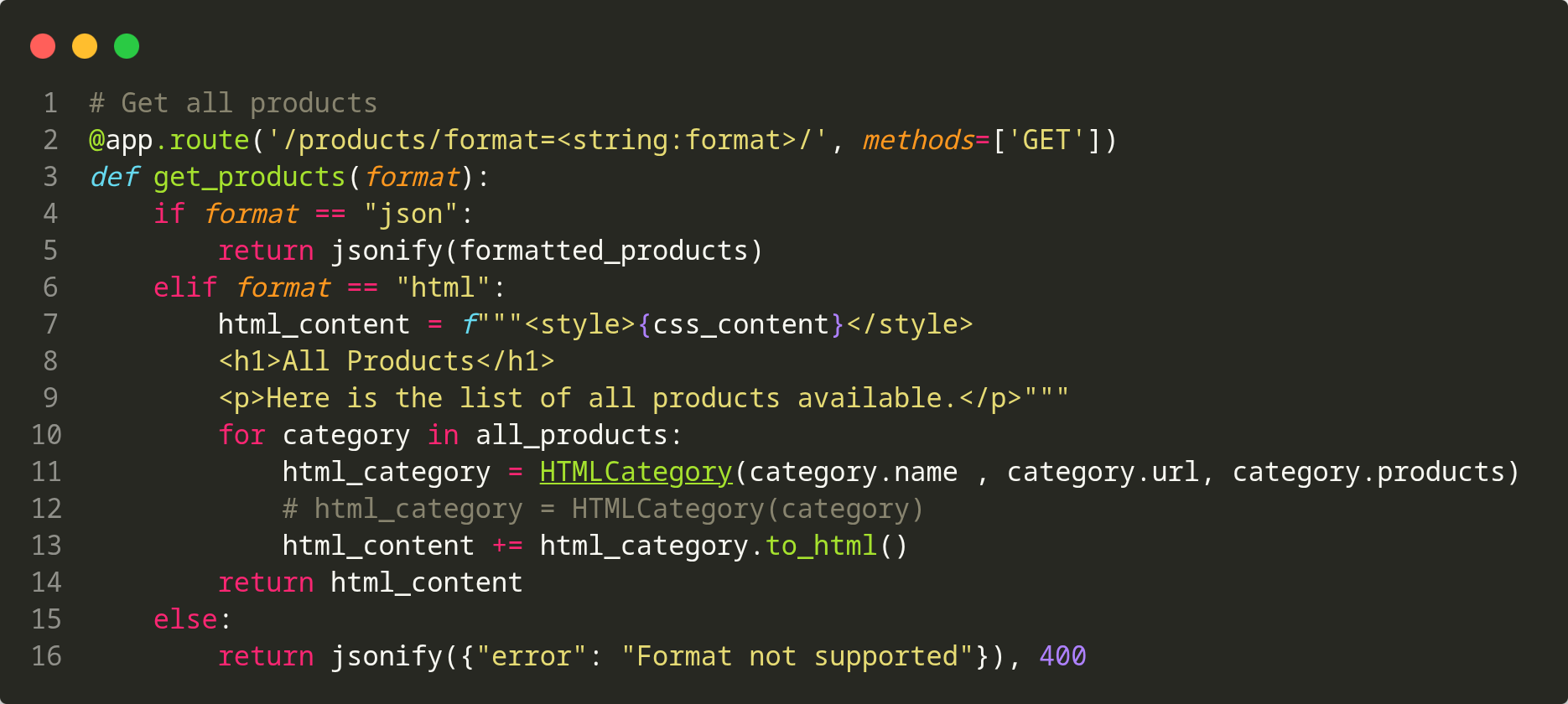
🔌 API REST Flask
- GET /products/format=json/ : Tous les produits en JSON formaté
- GET /products/format=html/ : Rendu HTML avec CSS (catalogue produits)
- GET /products/{REF}/format=json/ : Un produit par référence (JSON)
- GET /products/{REF}/format=html/ : Fiche produit HTML (détails + liens)
- GET /products/myproducts/key={API_KEY}/format=json/ : Produits filtrés (config USED_PRODUCTS_REF) — auth par clé
- GET /products/myproducts/key={API_KEY}/format=html/ : Affichage HTML des produits entreprise
🔐 Sécurité & Configuration
- API Key : Endpoint /myproducts nécessite key=MY_KEY (config USED_PRODUCTS_REF)
- USED_PRODUCTS_REF : Liste blanche des références produits pour l'entreprise
- Constants externalisées : CONST.py (URLs, selectors, paths) → maintenabilité
- Exception Handling : Try/except systématique, logging errors
- Path Abstraction : Pathlib pour chemins cross-platform
💡 Compétences démontrées
- Web Scraping : BeautifulSoup (parsing HTML), CSS selectors, pagination
- HTTP Requests : Sessions, stream downloads, retry logic, error handling
- Python OOP : Classes Product/Category, méthodes de sérialisation
- File I/O : JSON read/write (encoding UTF-8), PDF/image streaming
- Flask REST : Routes, content negotiation (JSON/HTML), query params, auth
- Automation : End-to-end pipeline (scrape → JSON → download → serve)
- Logging & Debugging : Traces complètes pour troubleshooting
- Code Organization : Séparation concerns (scraping, download, API)
🏢 Contexte réel (stage découverte)
- Besoin entreprise : Centraliser fiches techniques/sécurité produits Eyrein
- Automatisation : Évite collecte manuelle + mise à jour régulière
- Distribution : API accessible (JSON/HTML) pour intégration site web
- Traçabilité : JSON = source unique truth (versionnage Git possible)
- Scalabilité : Facile ajouter produits / catégories
✨ Points clés
- Requests.Session() : Gestion efficace connexions HTTP (pooling)
- BeautifulSoup CSS selectors : Plus puissant que regex pour parsing HTML
- Stream-based downloads : Gestion mémoire pour gros PDFs
- Deduplication set() : O(1) lookup pour éviter doublons
- JSON persistence : Format universel (JS, Python, PHP, etc.)
- Flask routing : Format et content-negotiation via query params
- Logging patterns : Structured logging (timestamp, level, message)
📚 Stack & Dépendances
- requests : HTTP client moderne + sessions
- beautifulsoup4 : Parsing HTML/XML + CSS selectors
- flask : Micro-framework REST
- Pathlib : File path abstraction (stdlib)
- json : Sérialisation (stdlib)
- logging : Structured logging (stdlib)
- zipfile : Compression d'archives (stdlib)
Un projet end-to-end qui démontre ma capacité à automatiser des tâches répétitives : scraping, transformation données, téléchargement, exposition API. Production-ready avec gestion erreurs et logging.
